HyperSpace: Web Browsing with Visualisation
Andrew Wood, School of Computer Science, University of Birmingham
A.M.Wood@cs.bham.ac.uk
http://www.cs.bham.ac.uk/~amw/
Nick Drew, School of Computer Science, University of Birmingham
N.S.Drew@cs.bham.ac.uk
http://www.cs.bham.ac.uk/~nsd/
Russell Beale, School of Computer Science, University of Birmingham
R.Beale@cs.bham.ac.uk
http://www.cs.bham.ac.uk/~rxb/
Bob Hendley, School of Computer Science, University of Birmingham
R.J.Hendley@cs.bham.ac.uk
http://www.cs.bham.ac.uk/~rjh/
School of Computer Science
The University of Birmingham
Edgbaston, Birmingham B15 2TT
United Kingdom
-
Keywords:
-
World-Wide Web Visualisation, Browsing, Mapping, Virtual Reality
Introduction
The W3 is a vast collection of geographically distributed, essentially
unorganised information, and whilst there is likely to be the answer to
your question out there, it can be impossible to find it. Worse, once you
have discovered relevant information, it is unclear where to go next to
find further information, and even when you choose an interesting path,
rediscovering one that you noticed earlier is difficult. Users become lost
in the maze of hypertext links, and need support in navigating the web.
HyperSpace
HyperSpace is a prototype World-Wide Web visualiser that can be used to
display the organisation of areas of the web. It structures the information
not according to geographical location, but according to a user-defined
structure, which means that related topics are displayed adjacent to each
other, and unrelated topics are spatially separated.
Each page on the web is represented as a sphere, and links from one
page to another are represented as links between the spheres. These spheres
and links are placed into a 3-d virtual reality system, initially randomly.
The chaotic and unstructured mesh of nodes and links is then allowed to
self-organise according to some imposed physics within the reality. Nodes
repel each other, whilst links provide an attractive force. Thus, unrelated
areas that do not have links between them are pushed apart, whilst highly-interrelated
work is pulled together and clustered in the same region of space.
Characteristic structures form that serve as landmarks to aid and guide
the navigation process. From any page that has been visited, HyperSpace
provides a view of all the pages that are linked to that node; when you
encounter a page for the first time you can immediately see all the other
pages that lead away from it; the viewer also shows all the incoming links
from any of the other pages that it knows about.
The System
Our system collects URLs using an adapted browser that passes the current
URL to an external program; each time the user moves to a new page the
new URL is passed out. This is picked up by a separate process that fetches
the page again (from a local cache), parses the content and extracts all
the links and the current page title. All the data is collated together,
to be used by the HyperSpace viewer. This assigns each URL a sphere whose
size is dependent on the number of links and a random spatial position.
The system can then self-organise (collapse) into the organic structures
shown below.
Some Results

A ray-traced
image of the initial random structure reflected in one of the page
nodes, with an MPEG
movie showing the web structure moving from its starting chaotic structure
to its final organisation.

A ray-traced
image of the structure formed by a fully explored set of home pages
(notice how pages that have not yet been explored tend to lie on the outskirts
of the structure).
A ray-traced
image of the structure of several index pages on similar topics.
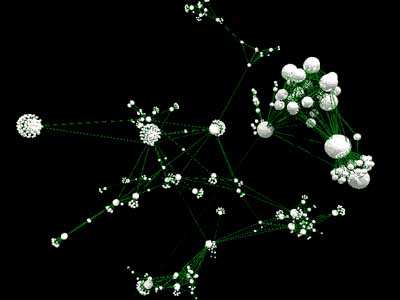
A ray-traced image of the structure of over 750 pages. In the foreground
is a highly cross-referenced set of manual pages, further in the distance
several large index pages can be seen.
A ray-traced
image of the structure formed from an actually browsing session (notice
the `constellations' formed by completely separate unconnected pages).
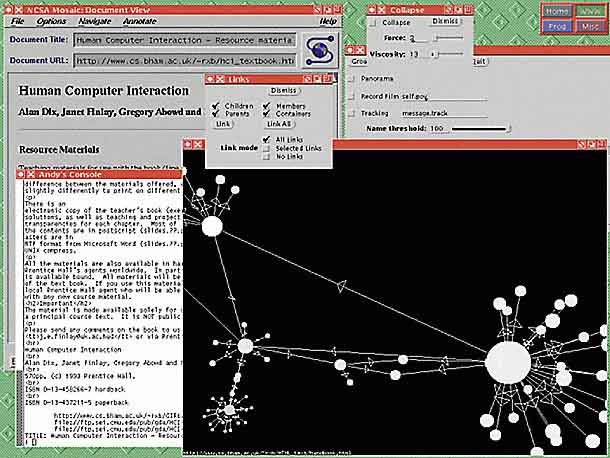
A screen-shot of the HyperSpace system in use, with the viewer window,
Mosaic browser, and various control panels.

A screen-shot
of the viewer window with the structure only showing the links from the
selected page [1], and also the names of pages (unexplored pages simply
show their URL).
Future Developments
The current system allows users to view the `map' of their progress through
the web at any stage during their exploration, but on each occasion the
view has to be reloaded and collapsed (with a significant time overhead).
We are currently developing a version of the viewer that will add the pages
as the user accesses them, and will re-organise itself automatically; allowing
the user to see immediately where they are. The viewer and the browser
will also be synchronised, enabling the user to access a page in the browser
simply by clicking on its sphere in the viewer.
We are also working towards adding extra customisation features to the
viewer, allowing the user to specify the size, shape, colour and names
of the nodes. Changing each of these parameters, even subtly, can affect
which features the visualisation highlights. For example, currently the
size of the sphere is related to the number of links that are present on
the page, in order to allow enough space to render the objects. It may
be better to collect usage or response statistics on that node and set
the sphere size accordingly, thus cueing the user as to popular or rapidly
accessible pages. Other planned improvements and enhancements are detailed
in [HSV95].
We believe that allowing users to visualise the web in this way will
help them to orient themselves within its information landscape - allowing
them to make more effective use of the many resources that the web provides.
-
[1]
-
The viewer display without links has been nicknamed affectionately `cauliflower
space'.
-
[HSV95]
-
Wood, A, Beale, R, Drew, N & Hendley, R, "HyperSpace: A World-Wide
Web Visualiser and its implications for Collaborative Browsing and Software
Agents", submitted to HCI'95, UK.





