Origins and Nature of the Internet in Australia
© Xamax Consultancy Pty Ltd, 1998-2004
Version of 29 January 2004
This document is an extract from the original document : mainly the Chapter 3 of http://www.anu.edu.au/people/Roger.Clarke/II/OzI04.html
Abstract
The Internet emerged in the U.S. engineering research community between 1969 and 1983, an outgrowth of the marriage between computing and communications technologies. Australian computing researchers had less advanced but cost-effective mechanisms in place at the time, and adopted the Internet protocols only when they had reached a level of maturity. Rapid progress was made from 1989 onwards.
By 1993-94, the U.S. Internet backbones were in transition from an academic infrastructure to a more conventional business model. Australian use by individuals, business and government grew almost as fast as it did in the fastest adopting countries, the U.S.A. and Scandinavia. As a result, a new business model was implemented in Australia in 1994-95.
The rapid maturation since then has placed Australia and Australians in a strong position to exploit the information infrastructure that the Internet represents, and to participate aggressively in the inevitably rapid change of the next 5-10 years. Unfortunately, the country's future is being undermined by the Government's failure to re-structure the telecommunications sector. Instead of a hierarchy of service layers with effective competition in the upper layers, the Internet industry is still dominated by a single, massive, vertically-integrated corporation.
Contents
- 1. Introduction
- 2. The Marriage of Computing and Communications
- 3. The Emergence of the Internet
- 4. The Beginnings of the Australian Internet
- 5. The Emergence of the Public Internet in Australia
- 6. The Contemporary Public Internet
- 7. The Future of the Internet in Australia
- References
- Additional Resources
1. Introduction
Australian historians have yet to turn their attention to the Internet; engineers care little for recording their activities for posterity; and there is as yet no powerful organisation that wants a court history. As a result, there is remarkably little documentation of the first decade of the Internet in Australia. This paper draws on available resources in order to provide an outline of that history that is sufficiently detailed to support strategy and policy discussions.
Commentators on cyberspace behaviour and regulation are at dire risk of making unfounded assumptions about the Internet, because of the many myths embedded in the metaphors that have been used to explain the Internet. In order to provide an antidote against ill-informed discussion, this paper includes background information on the technology and its governance institutions and processes.
The paper commences with some relevant aspects of the history of computing, and of communications. It then reviews the emergence of the Internet in the U.S.A. from 1969 onwards. The early history of academic use of the Internet in Australia is traced, prior to the first watershed in June 1989, and the second in May 1994. This is followed by an overview of the history of the open, public Internet in Australia, and assessments of the infrastructure, the industry structure and governance at the beginning of 2004, and likely near-future directions.
3. The Emergence of the Internet
This section reviews the history of the Internet, including its key technical features, its design principles and governance arrangements, its use, and some of its implications. This information is critical to a proper appreciation of the specifically Australian material that follows; but many readers of this journal will be able to skim the early sub-sections.
3.1 Origins and Growth Within the U.S.A. - 1969 to 1990
In the late 1960s, researchers in the U.S. gained funding from that country's Defense Advanced Research Projects Agency (DARPA) to develop a computer network concept. In September 1969, the first pair of nodes was installed at the University of California, Los Angeles campus (UCLA). The first external link was to Stanford Research Institute (SRI), several hundred kilometers north. The network was dubbed ARPANET. During the 1970s, there were developments in the architecture and the technology, and progressive growth in both the number of computers connected to ARPANET and in traffic.
The two crucial protocols that were the foundation for the subsequent explosion were implemented network-wide in 1983. These were the Transmission Control Protocol (TCP) and the Internet Protocol (IP), and the network came to be referred to as the Internet. In 1985, the numerical IP-address was supplemented by domain-names, to provide more human-friendly ways of referring to and remembering network location-identifiers.
Through the 1980s, the Internet became well-established infrastructure, and unleashed rapid growth. A number of networks had emerged that linked U.S. universities using various proprietary protocols (such as IBM's SNA and Digital's DECnet) and international standards (e.g. X.25). During the second half of the 1980s, the decision was taken to migrate key networks across to the Internet protocol suite. As this plan was implemented, the number of hosts connected to the Internet grew from 1,000 in 1984, to 10,000 in 1987, 60,000 in 1988, and 100,000 in 1989. Not only did the Internet grow substantially in size, but the user-base also became much more diverse, although still restricted to universities and other research establishments. By 1990, the Internet protocol suite dominated all other wide-area network protocols.
Authoritative reference on the origins and early years of the Internet include Hafner & Lyon (1996), Abbate (1999) and Leiner et al. (2000). A useful timeline is provided by Zakon (1993-). For a history intended to be readily accessible to non-specialists, see Griffiths (2002). Other sources are indexed by the Internet Society (ISOC).
3.2 The Nature of the Internet
The Internet is an infrastructure, in the sense in which that term is used to refer to the electricity grid, water reticulation pipework, and the networks of track, macadam and re-fuelling facilities that support rail and road transport. Rather than energy, water, cargo or passengers, the payload carried by the information infrastructure is messages.
The term 'Internet' has come to be used in a variety of ways. Many authors are careless in their usage of the term, and considerable confusion can arise. Firstly, from the perspective of the people who use it, the Internet is a vague, mostly unseen, collection of resources that enable communications between one's own device and devices elsewhere. Exhibit 3.2 provides a graphical depiction of that interpretation of the term 'Internet'.
Exhibit 3.2: The Internet As Perceived by Users
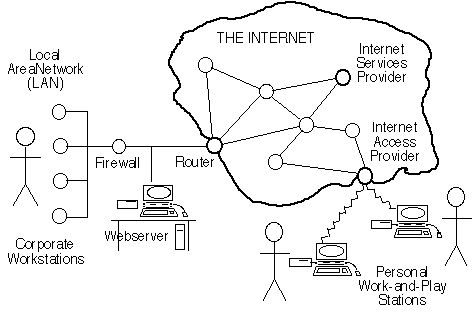
From a technical perspective, the term Internet refers to a particular collection of computer networks which are inter-connected by means of a particular set of protocols usefully called 'the Internet Protocol Suite', but which is frequently referred to using the names of the two central protocols, 'TCP/IP'.
The term 'internet' (with a lower-case 'i') refers to any set of networks interconnected using the Internet Protocol Suite. Many networks exist within companies, and indeed within people's homes, which are internets, and which may or may not have a connection with any other network. The Internet (with an upper-case 'I'), or sometimes 'the open, public Internet', is used to refer to the largest set of networks interconnected using the Internet Protocol Suite.
Additional terms that are in common use are Intranet, which is correctly used to refer to a set of networks that are internal to a single organisation, and that are interconnected using the Internet Protocol Suite (although it is sometimes used more loosely, to refer to an organisation's internal networks, irrespective of the protocols used). An Extranet is a set of networks within a group of partnered organisations, that are interconnected using the Internet Protocol Suite.
3.3 Internet Technology
A network comprises nodes (computers) and arcs (means whereby messages can be transmitted between the nodes). A network suffers from fragility if individual nodes are dependent on only a very few arcs or a very few other nodes. Networks are more reliable if they involve a large amount of redundancy, that is to say that they comprise many computers performing similar functions, connected by many different paths. The Internet features multiple connections among many nodes. Hence, when (not if) individual elements fail, the Internet's multiply-connected topology has the characteristics of robustness (the ability to continue to function despite adverse events), and resilience (the ability to be recovered quickly and cleanly after failure). The Internet also has the characteristic of scalability, that is to say that it supports the addition of nodes and arcs without interruptions, and thereby can expand rapidly without the serious growing pains that many other topologies and technologies suffer.
The conception of the Internet protocols took place during the 1960s and 1970s, at the height of the Cold War era. Military strategists were concerned about the potentially devastating impact of neutron bomb explosions on electronic componentry, and consequently placed great stress on robustness and resilience (or, to use terms of that period, 'survivability' and 'fail-soft'). These characteristics were not formal requirements of the Internet, and the frequently-repeated claims that 'the Internet was designed to withstand a neutron bomb' are not accurate. On the other hand, those design characteristics were in the designers' minds at the time.
The networks that had been designed to support voice-conversations provided a dedicated, switched path to the caller and the callee for the duration of the call, and then released all of the segments for use by other callers. Data networks were designed to apply a very different principle. Messages were divided into relatively small blocks of data, commonly referred to as packets. Packets despatched by many senders were then interleaved, enabling efficient use of a single infrastructure by many people at the same time. This is referred to as a packet-switched network, in comparison with the telephony PSTN, which is a circuit-switched network. The functioning of a packet-switched network can be explained using the metaphor of a postal system (Clarke 1998).
For devices to communicate successfully over a packet-switched network, it is necessary for them to work to the same rules. A set of rules of this kind is called a protocol. Rather than a single protocol, the workings of packet-switched networks, including the Internet, were conceived as a hierarchy of layers. This has the advantage that different solutions can be substituted for one another at each layer. For example, the underlying transmission medium can be twisted-pair copper cable (which exists in vast quantities because that was the dominant form of wiring for voice services for a century), co-axial cable (which is used for cable-TV and for Ethernet), fibre-optic cable, or a wireless medium using some part of the electromagnetic spectrum. This layering provides enormous flexibility, which has underpinned the rapid changes that have occurred in Internet services.
The deepest layers enable sending devices to divide large messages into smaller packets, and generate signals on the transmission medium that represent the content of the packets; and enable receiving devices to interpret those signals in order to retrieve the contents, and to re-assemble the original message. The mid-layer protocols provide a means of getting the messages to the right place, and the upper-layer protocols use the contents of the messages in order to deliver services. Exhibit 3.3 provides an overview of the layers as they are currently perceived.
Exhibit 3.3: The Current Layers of Internet Protocols
| Layer | Function | Orientation | Examples |
| Application | Delivery of data to an application | Message | HTTP (the Web), SMTP (email despatch) |
| Transport | Delivery of data to a node | Segment | TCP, UDP |
| Network | Data addressing and transmission | Datagram | IP |
| Link | Network access | Packet | Ethernet, PPP |
| Physical | Handle Signals on a Medium | Signals | CSMA/CD, ADSL |
For a device to be able to use the Internet, it needs access to software that implements the particular protocols relevant to the particular kind of access that they are interested in having, and to the particular transmission medium that connects them to other devices.
Messages pass across the Internet as a result of co-operation among many devices. Those devices may be under the control of many different organisations and individuals, who may be in many different physical locations, and may be subject to many different jurisdictions. The path that any particular message follows between the sender and recipient is decided in 'real time', under program control, without direct human intervention, and may vary considerably, depending on such factors as device and channel outages, and traffic congestion. Depending on its size, a message may be spread across many packets, and the packets that make up a message do not necessarily follow the same paths to their destination.
The detailed topology of the Internet at any particular time is in principle knowable. In practice, however, it is not, because of its size, its complex and dynamic nature, and the highly dispersed manner in which coordination is achieved. Control would be facilitated if key functions were more centralised. But centralisation produces bottlenecks and single-points-of-failure; and that would be detrimental to the Internet's important characteristics of robustness, resilience and scalability.
Further details of Internet technology are provided in Clarke et al. (1998), and in texts such as Black (2000), Hall (2000) and Gralla (2002).
3.4 Internet Application Protocols and Services
The application protocol layer utilises the transmission medium and the lower and middle protocol layers as an infrastructure, in order to deliver services. Some services are provided by computers for other computers, some by computers but for people, and some by people and for people. Key services that are available over the underlying infrastructure include e-mail and the World Wide Web (which together dominate Internet traffic volumes), file transfer and news (also referred to as 'netnews' and by its original name 'Usenet news'). There are, however, several score other services, some of which have great significance to particular kinds of users, or as enablers of better-known services.
During the early years, the services that were available were primarily remote login to distant machines (using rlogin and telnet from 1972), email (from 1972), and file transfer protocol (ftp, from 1973). In 1973, email represented 75% of all ARPANET traffic. By 1975, mailing lists were supported, and by 1979-82 emoticons such as (:-)} were becoming established. By 1980, MUDs and bulletin boards existed. The email service in use in 2004 was standardised as early as 1982. Synchronous multi-person conversations were supported from 1988 by Internet Relay Chat. This was also significant because the innovation was developed in Finland, whereas a very large proportion of the technology had been, and continues to be, developed within the U.S.A.
By 1990, over 100,000 hosts were connected, and innovation in application-layer protocols, and hence in services, accelerated. Between 1990 and 1994, a succession of content-provision, content-discovery and content-access services were released, as existing news and bulletin-board arrangements were reticulated over the Internet, and then enhanced protocols were developed, including archie (an indexing tool for ftp sites developed in Canada), the various 'gopher' systems (generic menu-driven systems for accessing files, supported by the veronica discovery tool), and Brewster Kahle's WAIS content search engines. Between 1991 and 1994, the World Wide Web emerged, from an Englishman and a Frenchman working in Switzerland; and in due course the Web swamped all of the other content-publishing services. By 1995, it was already carrying the largest traffic-volume of any application-layer protocol.
Exhibit 3.4, which is a revised version of an exhibit in Clarke (1994c), provides a classification scheme for the services available over the Internet.
Exhibit 3.4: A Taxonomy of Internet Services
- Computers Services Provided for Other
Computers:
- Access to Processing Services, in particular the use of spare capacity on under-utilised machines (e.g. SETI@home)
- Encrypted Channel Services (e.g. SSL/TLS)
- Clock Synchronisation Services (in particular, ntp)
- Computer Services Provided for Individual
People:
- Remote Login Services (e.g. rlogin, telnet, ssh)
- Reference Services, including:
- newsgroups (i.e. nntp), bulletin-boards and conferences
- file transfer tools (e.g. ftp)
- multi-media file display tools (in particular the Web)
- Discovery Services, including:
- ftp file directory search tools (e.g. archie)
- structured file directories on the Web (e.g. Yahoo)
- search-engines on the Web (e.g. Google)
- structured directories (e.g. LDAP)
- Software Agents, including:
- mail-filtering agents
- news-gathering, filtering and presentation agents
- content aggregation/syndication agents (e.g. RSS)
- Human Communication Services - Different-Time /
Asynchronous
- Services for Pairs of People, including:
- person-to-person email (in particular, smtp and pop/imap)
- attachments, to enable the transmission of files containing data such as data-tables, diagrams and images (using the MIME standard)
- document display and annotation (e.g. Word revision-markings)
- Services for Groups of People, including:
- mailing lists, which may be:
- self-maintained as part of each individual's address book
- remotely maintained list-servers (e.g. listproc, majordomo, mailman)
- document display and annotation (e.g. Wiki)
- workflow tools, to manage document flows and action-sequences
- group decision support systems, supporting processes such as voting
- mailing lists, which may be:
- Services for Pairs of People, including:
- Human Communication Services - Same-Time /
Synchronous
- Services for Pairs of People, including:
- text-based chat tools (e.g. IRC, ICQ, instant messaging)
- voice conversation tools (e.g. VoIP)
- video-and-voice conversation tools (e.g. CU-See-Me)
- Services for Groups of People, including:
- text-based meeting-spaces (e.g. IRC and ICQ applied with discipline)
- voice tele-conferencing (e.g. VoIP)
- video-conferencing tools
- document display and annotation (e.g. shared whiteboard)
- group negotiation and decision support systems
- group visualisation tools and multi-user game-spaces
- Services for Pairs of People, including:
3.5 Internet Design Principles and Governance
This section provides an outline of the manner in which the Internet's architecture, protocols and operations are sustained. It commences by outlining some important design principles, which are rather different from those that guide most large undertakings. Descriptions are then provided of the institutions and processes involved in maintaining and developing the Internet's architecture, and in its operations. A final sub-section notes the current tensions in the area.
(1) Design Principles
It has been crucial to the success of Internet technology that it depends on few centralised functions, and that the focus is on coordination among many, rather than on control by a few. There was and is no requirements statement. There was and is no master design specification. There are several hundred specifications for particular features; but most of these were written after demonstration software had already been implemented. The Internet shows remarkable tolerance for prototypes and experiments.
Some principles can be discerned that have guided, and continue to guide, the development of the Internet's architecture:
- distribution of functions. Many different functions have to be performed in order that messages can be delivered and services provided. Those functions are not inherently centralised, but rather are able to be distributed across a large number of participating nodes;
- egalitarianism. Some computers perform special functions of a technical nature; but most functions are capable of being performed by many different nodes in the network. Robustness is achieved through decentralisation of responsibilities;
- distributed directories. In particular, the various directories that need to exist in order to determine possible paths a message can take are not stored in a single location, but distributed across a large number of nodes;
- multiple connection paths. Many nodes are not connected to just a single other node, but to multiple other nodes. This results in a large number of possible paths that a message can use in order to reach to its intended target, and thereby contributes to the Internet's resilience;
- collaborative control over the few centralised functions. The functions that do need to have some degree of centralisation have been the subject of collaborative processes among peers, rather than authoritarian control by one or more governments or corporations (although, as discussed later, that may be changing);
- collaborative design and standards-setting. The technical specifications that determine how the Internet is constructed and operates have also been determined by collaboration within open fora, and not by fiat of governments or corporations (although powerful organisations are increasingly seeking to impose their interests, frequently by means that are neither open nor collaborative).
(2) Architectural Governance
The governance of the Internet has demonstrated much of the same constructive looseness that characterises its design. During the early years, the institutions were merely informal groups, and the processes were merely understandings among engineers intent on making something work. Although there have been employed staff since the mid-1990s, the vast majority of the work is undertaken by some hundreds of individuals on a part-time, voluntary, unpaid basis. For those who travel to meetings, the costs are covered in most cases by their employers.
The first formal organisational element was the Internet Configuration Control Board (ICCB), established by ARPA in 1979. This became the Internet Activities Board in 1983 and later the Internet Architecture Board (IAB), which continues to operate as "the coordinating committee for Internet design, engineering and management" (IETF 1990). It is unincorporated, and operates merely as one committee among many.
The designing and refinement of protocol specifications is undertaken by Working Groups. At the end of 2003, there were 132 active Groups, with a further 325 Groups no longer operational. Proposals and working documents are published as 'Internet Drafts'. Some 2,500 were current as at the end of 2003. Unfortunately for would-be historians, they are not numbered, and not archived, making it very difficult for outsiders to re-construct the history of critical ideas.
Completed specifications are published as RFCs. This term derives from the expression 'Request For Comment', but 'RFC' is applied ambiguously. At the end of 2003, the series comprised 3,666 documents, including 38 informational documents and 77 best practices descriptions, many hundreds of obsolete specifications, many hundreds of specifications for protocols and features that have been or are now little-used, and several hundred specifications that define the Internet, including a small proportion of formally adopted standards.
The Working Groups are coordinated by the Internet Engineering Task Force (IETF). This "is a loosely self-organized group of people who contribute to the engineering and evolution of Internet technologies. It is the principal body engaged in the development of new Internet standard specifications. The IETF is unusual in that it exists as a collection of happenings, but is not a corporation and has no board of directors, no members, and no dues" (IETF 2001). A committee called the Internet Engineering Steering Group (IESG) acts as a review and approval body for new specifications.
Although all of the key bodies described above are unincorporated, they have had an "organizational home" in the form of the Internet Society (ISOC) since 1992. This is a "professional membership organization of Internet experts ... with more than 150 organization and 16,000 individual members in over 180 countries. ... [It] comments on policies and practices and oversees a number of other boards and task forces dealing with network policy issues". It drew the various committees under its umbrella by issuing them with 'charters' to perform their functions.
There are several other organisations that play roles in particular areas. The deepest-nested layers dealing with transmission media are the domain of an international professional association, the Institute of Electrical and Electronic Engineers (IEEE) and the International Telecommunications Union (ITU), an international authority whose membership encompasses telecommunication policy-makers and regulators, network operators, equipment manufacturers, hardware and software developers, regional standards-making organizations and financing institutions. Meanwhile, the many protocols associated with the Web are the province of an industry association, the World Wide Web Consortium (W3C). ISOC provides a catalogue of Internet standards organisations.
Although in many cases the committees and Working Groups are dominated by U.S. citizens and others resident in the U.S.A., many non-Americans are very active in Internet governance processes, and that has been the case since at least the mid-1990s. A number of Australians are active and influential participants. In particular, Geoff Huston spent some years as Secretary of ISOC and is currently Executive Director of the IAB; Paul Twomey is President of ICANN; and Paul Wilson is Director-General of APNIC. In addition, many Australian engineers contribute to IETF and W3C Working Groups.
(3) Operational Governance
The bodies that are responsible for governance of the architecture also play key roles in relation to its ongoing operations, particularly the IAB and IETF. A further important organisation is the Internet Assigned Numbers Authority (IANA).
The first critical function is the allocation of IP-addresses, the numerical identifiers of Internet locations. Until the early 1990s, IANA performed that function. Starting in 1992, the role was progressively migrated to a small number of regional registries, although IANA still manages the pool of unallocated addresses.
In the U.S.A., the Government originally funded the registry functions through an organisation called InterNIC; but since 1997 they have been performed by a membership-based organisation, ARIN (American Registry for Internet Numbers), which also covers Canada, and sub-Saharan Africa. The other registries are also membership-based organisations: RIPE NCC (Réseaux IP Européens Network Coordination Centre), which covers not only Europe but also the Middle East, the North of Africa and parts of Asia; and APNIC (Asia-Pacific Network Information Centre), which covers most of Asia, plus Oceania. In late 2002, support for Latin America and the Caribbean was passed from ARIN to LACNIC (Latin America and Caribbean Internet Addresses Registry). An authoritative but very readable paper on the history and current arrangements in relation to IP-address management is Karrenberg et al. (2001).
A second important role is the management of the wide variety of parameter-values that are needed to support Internet protocols. Many years ago, the Information Sciences Institute (ISI) of the University of Southern California contracted with DARPA to perform these functions. It assigned the work to IANA, which, like so many other organisations, is not incorporated, and was for many years essentially one person, Jon Postel.
A third important function is the establishment and management of domain-names. A domain-name is an alphanumeric identifier for Internet locations, which is easier for people to use than the underlying numerical IP-address. The scheme was devised around the time that the ARPANET spawned the Internet. Increasingly, domain-names also provide separation of the name of a service from its network-location.
From 1983 onwards, IANA played a central role in relation to domain-names. It assessed applications to manage the country code top level domains (ccTLDs, such as .au, of which there are over 200), and was responsible for evaluating proposed additions to the established generic top level domains (gTLDs, such as .com and .org, of which there are currently 14). The management thereafter is hierarchical, based on the authorities delegated by IANA for each of the ccTLDs and gTLDs. The IANA register shows, for example, that the Registrar for .au is AuDA, and that for .org is Public Interest Registry (PIR) (a U.S. not-for-profit corporation established by ISOC).
In recent years the management of domain-names has been a highly visible symbol of attempts to commercialise the Internet. There is currently a movement to shift the responsibility from IANA to a new organisation, the Generic Names Supporting Organization (GNSO). This is discussed in the following sub-section.
Translating the domain-name into the IP-address is called "resolving the domain name." This is performed by a highly distributed system involving tens of thousands of servers throughout the world, called the domain name system (DNS). Through the course of development of the Internet, IANA has played a central role in the management of the Domain Name System (DNS), including management of the root-servers. (There are 13 alternative root-servers, 10 in the U.S.A., and 1 in each of Sweden, the U.K. and Japan).
A more detailed but very accessible overview of cyberspace governance is in Caslon (2003b and 2003c).
(4) The Ongoing Risk of Bureaucratisation
For three decades, the community of engineers that are the institutions, and whose efforts are the processes, of Internet governance, have steadfastly and fairly successfully resisted the imposition of legal and administrative strictures.
But as the Internet has matured into the world's primary information infrastructure, there has been increasing discomfort among bureaucracies about the 'constructive looseness' of Internet governance institutions and processes. They are especially concerned that these bodies operate to a considerable degree beyond the reach of national governments and even of international bodies such as the U.N. and the ITU. Hence, since the late 1990s, there have been increasingly strenuous efforts by governments to impose bureaucratic order on Internet governance.
The early running has been made by the U.S. government. Not entirely unreasonably, it considers that it has a substantial interest in the Internet, and, through a number of contracts for services, the legal right to impose some requirements on at least some of the Internet's institutions: "When the Internet was small, the DNS was run by a combination of volunteers, the National Science Foundation (NSF), and U.S. government civilian and military contractors and grant recipients. As the paymaster for these contractors, the U.S. government became the de facto ruler of the DNS" (ICANNWatch 2001).
The U.S. government encouraged the emergence of a "not-for-profit corporation formed by private sector Internet stakeholders to administer policy for the Internet name and address system". The organisation that was formed was the Internet Corporation for Assigned Names and Numbers (ICANN). This has enabled measures to be imposed that would have been infeasible if the functions had been performed by a government agency.
ICANN has three segments:
- the Address Supporting Organization (ASO), which relates to IP-addresses;
- the Protocol Supporting Organization (PSO), which relates to the assignment of parameters for Internet protocols, and technical standards that let computers exchange information and manage communications over the Internet; and
- the Generic Names Supporting Organization (GNSO), which, despite the recent replacement of the term 'domain names' by 'generic names', appears to be limited in scope to domain names.
It is clear that these are intended to function as peak bodies, taking over from the pre-existing bodies, and forcing them to become participants in much more broadly-based fora. The hope was that ICANN would be able to encourage a degree of order without stunting the growth that has been achieved through a remarkably distributed (almost, dare one breathe the word, communitarian) undertaking.
Unfortunately, the organisation's constitution and behaviour have been contentious from the very beginning, and the situation remains vexed. A wide array of senior and well-respected members of the Internet community have accused ICANN of lack of representativeness, lack of openness (even denying information to its own Directors), lack of accountability, and abuse of power. A summary and references are at Clarke (2002).
Meanwhile, the rest of the world is concerned that Internet governance be not unduly subject to control by the U.S. government. The wording of the communiqué following the recent World Summit was diplomatic, but significant : "The international management of the Internet should be multilateral, transparent and democratic, with the full involvement of governments, the private sector, civil society and international organizations. ... International Internet governance issues should be addressed in a coordinated manner. We ask the Secretary-General of the United Nations to set up a working group on Internet governance, in an open and inclusive process that ensures a mechanism for the full and active participation of governments, the private sector and civil society from both developing and developed countries, involving relevant intergovernmental and international organizations and forums, to investigate and make proposals for action, as appropriate, on the governance of Internet by 2005" (WSIS 2003, at 48, 50). The wide-ranging disharmony between the U.S.A. and the rest of the world exists in cyberspace matters as well.
It remains to be seen whether the powerful interests that are benefitting from ICANN's policies will prevail, the organisation will be forced to establish less authoritarian policies and practices, or ICANN will be replaced by a more acceptable body, such as an enhanced IAB or a committee beholden to international organs.
3.6 Internet Use
The Internet is just an infrastructure, and the protocols and services are just tools. In order to understand their impacts and implications, it is necessary to appreciate what people have done with them.
The original conception had been that the ARPANET would connect computers. "By the second year of operation, however, an odd fact became clear. ARPANET's users had warped the computer-sharing network into a dedicated, high-speed, federally subsidized electronic post-office. The main traffic on ARPANET was not long-distance computing. Instead, it was news and personal messages. Researchers were using ARPANET to collaborate on projects, to trade notes on work, and eventually, to downright gossip and schmooze" (Sterling 1993).
The emphasis on human communications has continued through the second and third decades. Moreover, people participate in a shared hallucination that there is a virtual place or space within which they are interacting. The term most commonly used for this is 'cyberspace', coined by sci-fi author William Gibson in 1983. Gibson's virtual world was full of foreboding; but despite the dark overtones (or in ignorance of them), people cheerfully play in cyberspace. Its uses put varying emphases on connectivity and content. A general perception has been that content (typified by use of the Web) would overtake connectivity (typified by e-mail); but some feel that a balance between the two will always be evident Odlyzko (2001).
Associated with cyberspace behaviour is an ethos that developed during the pioneering era. The surge of newcomers appears to have to some degree subdued the old ethos; but in part they have adopted it, with the result that it is still very much in evidence. Exhibit 3.6 suggests the expectations that still appear to be commonly held among a significant proportion of Internet users:
Exhibit 3.6: Elements of Cyberspace Ethos
- Inter-Personal Communications. Many participants perceive cyberspace primarily as a context for interactions among individuals. They perceive organisations as enablers, as providers of resources, and as offerors of services, rather than as participants
- Internationalism / Universalism. Although the invention and initial implementation of the Internet were a primarily U.S. activity, participants mostly perceive it as a universal service. As the aphorism has it, 'there are no borders in cyberspace' (or at least there are none inherent in the architecture), and connectivity and content are technically open to anyone, irrespective of location or nationality
- Egalitarianism. Participants who are fulfilling particular roles in some services have more power than others. For example, in the case of moderators of e-lists and forums, this extends as far as blocking messages; and in the case of MUDs, a user who controls the space (a 'god' or 'wizard') can even exclude a particular identity or IP-address from participation. In most of the contexts created by Internet services, however, users do not experience a hierarchy of authority, and people behave as though they are, by and large, equal
- Openness. Information about the Internet's fundamental protocols and standards is readily accessible to those who seek it out (although that may not be the case with particular services, or with proprietary extensions to services)
- Participation. The Internet, and many of the services available over it, embody no inherent barriers against active participation by any party. Moreover, many services arise from collaborative activity among many individuals
- Communitarianism / Mutual Service. A feeling, common among many participants, is that they are part of one or more e-communities. As a result, they contribute to that community, and draw from it. Rather than being altruistic behaviour, this may reflect the alternative economics of deferred and indirect reciprocity prevalent in communities, which is rather different from the immediate and direct exchange that occurs in most markets
- Gratis Services. A vast amount of content and software is not only 'free as in liberty' but also 'free as in beer'. Moreover, the costs involved in establishing and running the Internet are hidden from the view of most users, and many perceive it to be gratis. In fact consumers do pay, in particular through telephone bills, equipment purchases and software licensing fees; and a great many people and organisations absorb costs because it suits their personal psyche or organisational business model to do so
- Freedoms. The combination of the various factors listed above give rise to an expectation among netizens that they enjoy greater freedoms in cyberspace than they have in physical space. This leads to resentment against activities by governments and corporations to constrain those freedoms
In every case, the popular perceptions of cyberspace are partly misguided; but those perceptions are an important part of the shared hallucination, and influence people's attitudes and behaviour.
On the other hand, some significant aspects of human behaviour carry over from the physical to the virtual world. The Internet attracts 'low-life', variously:
- unequivocally illegal (e.g. money-laundering, child pornography, financial fraud and commercial scams, and replicating copyrighted works for sale);
- regarded as inappropriate by some sections of society (e.g. on-line gambling, pornography, spyware, industrial espionage, and replicating copyrighted works for personal use); and
- excessively enthusiastic marketing (e.g. pop-up windows in browsers, spam, and non-consensual acquisition of consumer data).
Most discussions of ethics in the context of cyberspace are abstract and unhelpful. For an instrumentalist approach to cyberspace ethos, see Clarke (1999c).
3.7 Internet Implications
There are many ways in which the implications of the Internet can be analysed. One approach to the issues it raises is in Clarke (1999a). A broader perspective is needed, such as that offered in Exhibit 3.7.
Exhibit 3.7: Implications of Information Technologies
| 1940-1980 | 1980-2000 | 2000-2040 | |
| Processor Technology | Grosch's Law – Bigger is more efficient | VLSI / micros – More is more efficient | Commoditisation – Chips with everything |
| Network Technology | Star Centralised
| Multi-connected Decentralised | Wireless Ubiquitous |
| Processor Inter-Relationships | Master-Slave Control | Client-Server Request-Response | P2P Cooperation |
| Organisational Form | Hierarchies | Managed Networks | Self-managing Market/Networks |
| Software and Content | Closed Proprietary | Confusion and Tension | Open |
| Politics | Authoritarianism Intolerance | Confusion and Tension | Democracy and Frustrated Intolerance |
The implications of information technologies have changed significantly as computing and telecommunications have matured. From the invention of computing in about 1940, until about 1980, Grosch's Law held. This asserted that the processing power of computers grew exponentially with their cost. In other words, bigger was more efficient. This tendency towards centralised systems was supported by 'star' topologies for networks, with a master-slave relationship between a powerful machine at the 'hub' and a flotilla of 'dumb terminals' at the peripheries. The natural organisational form to utilise such infrastructure was hierarchical. Software was closed and proprietary. The political form that was served by the information technology of the era was authoritarian and intolerant of difference.
Grosch's Law was rescinded in about 1969, although the impact was felt in the marketplace only gradually (hence my suggestion of 1980 as the indicative year in which the old era ended). Very Large Scale Integrated (VLSI) circuitry spawned new machine architectures, and a new economics. Many micro-computers deliver not just greater flexibility than fewer larger machines, but also more power more cheaply. Networks quickly evolved into the multiply-connected, decentralised form that they currently have. Master-slave relationships gave way to so-called client-server arrangements, where intelligent remote workstations request services from dispersed devices scattered around an office, a campus, and the world. Organisations that take advantage of this technology exhibit not centralised form, but networked form. Software and politics were both thrown into confusion, from which they are only now beginning to emerge.
The final column offers a speculative interpretation of the next phase, which is returned to in the final section of the paper.
This section has demonstrated that the Internet is like no technology that preceded it. Discussion of strategic and policy aspects of the Internet cannot be sensibly undertaken without a sufficient grasp of the technology, infrastructure and governance of the Internet, and of the cyberspace behaviour of humans and their agents.
This document is an extract from the original document : mainly the Chapter 3 of http://www.anu.edu.au/people/Roger.Clarke/II/OzI04.html
| The Australian National University Visiting Fellow, Faculty of Engineering and Information Technology, Information Sciences Building Room 211 | Xamax Consultancy
Pty Ltd, ACN: 002 360 456 78 Sidaway St Chapman ACT 2611 AUSTRALIA Tel: +61 2 6288 1472, 6288 6916 |